
It also allows for longer training and reduces the need for other augmentation techniques. NOTE: The coefficients for the linear combinations of examples / labels are sampled from the beta distribution:
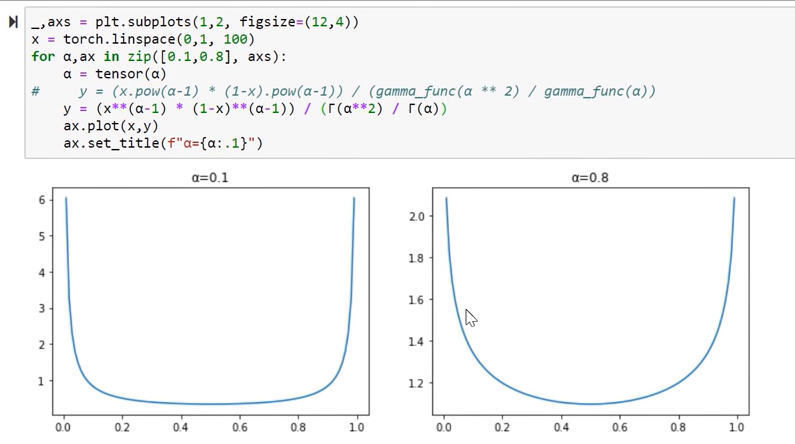
We are very likely to see some large portion of one image combined with a very tiny bit of another image - very rarely will we see images mixed in proportion of ~0.5. Also, we do not have to take linear combinations of the targets, instead we can do this:
