Question 14/27 fast.ai v4 lecture 5
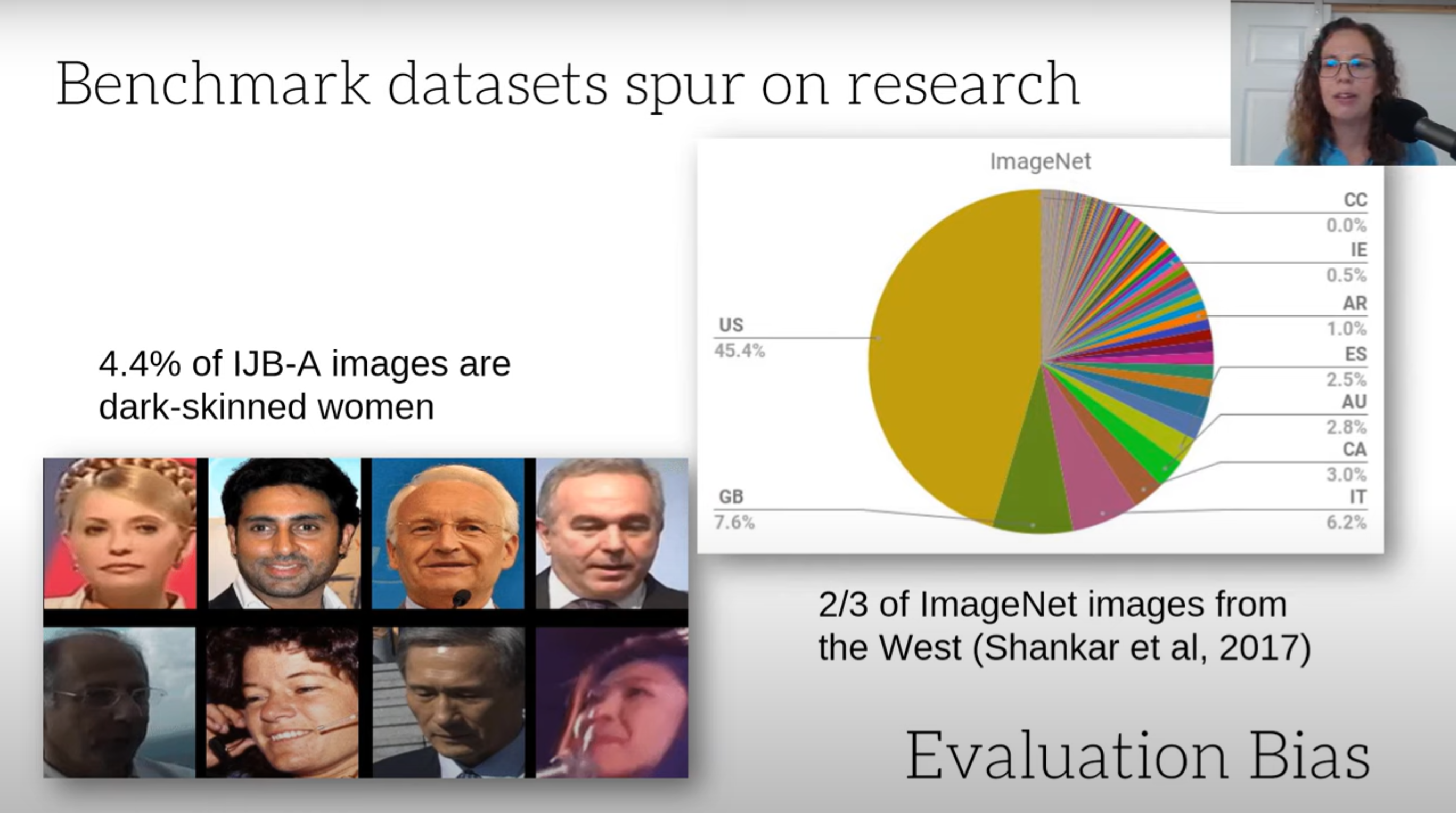
What is evaluation bias?
Answer
Relevant part of lecture
supplementary material
21 fairness definitions and their politics - a summary / talk by Arvind Narayanan
Answer
Relevant part of lecture
supplementary material