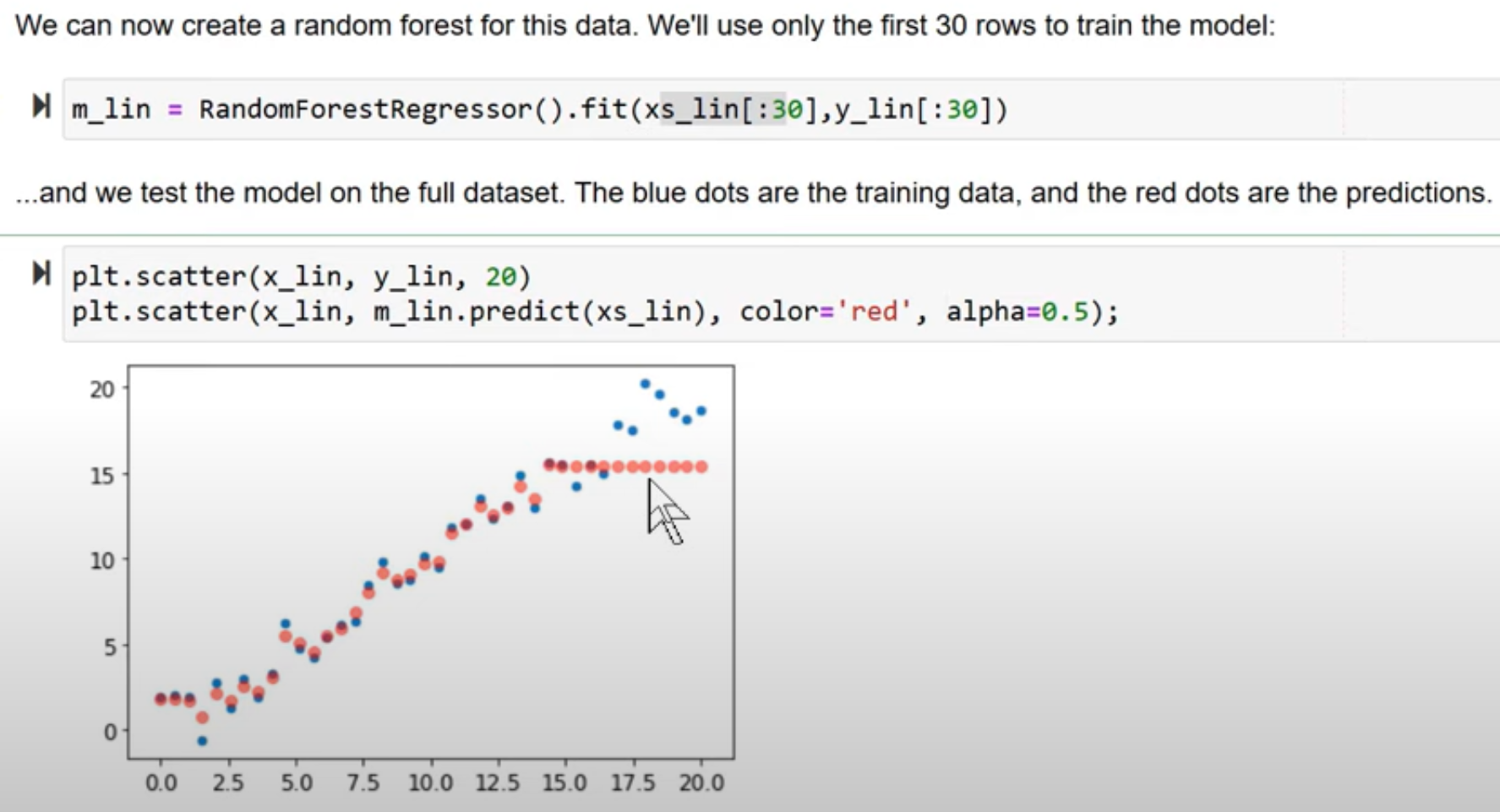
What is the extrapolation problem in the context of Random Forests?
Answer
Random Forest is just taking the average of predictions of a bunch of trees and the prediction of the tree is the average of the values in a leaf node (the averages are calculated based on values seen in the train set). Random Forests cannot extrapolate outside of the bounds of the data in the training set. This is a huge problem for things like time series prediction where there is an underlying trend. In a general sense, it is impossible for a Random Forest to extrapolate outside the types of data that it has seen. We need to make sure our validation set does not contain out of domain data.