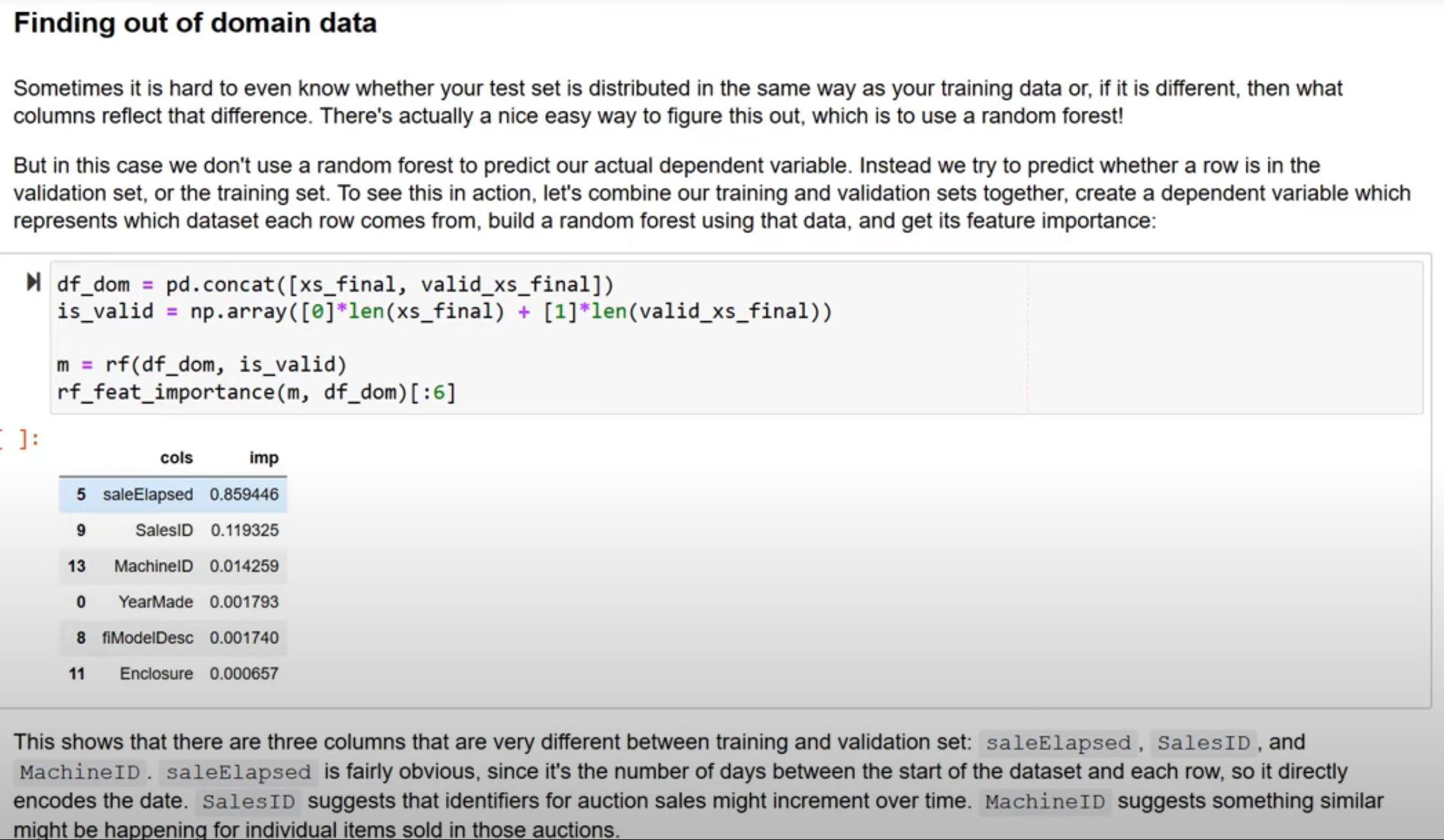
isvalid which contains 0 for everything in the training set and 1 for everything in the validation set. These are the values we will want our model to predict. The remaining values across the train and validation set become our independent variables.We train a Random Forest that strives to predict "is this row from the validation set or the training set?". If the validation and training sets are from the same distribution, they are not different, than this Random Forest should have zero predictive power. If that is not the case then it means that our validation and training sets are different. To find out the source of that difference we can use feature importance. <a href=https://aiquizzes.com/gcpimages/findingOODdata.png>