Question 4/13 fast.ai v3 lecture 9
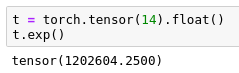
A common operation in implementing neural networks is raising e to the power of x. This can produce large floating point numbers.
What can happen when calculating gradients, or running calculations in general, with large floating point numbers?
Answer
Screenshot
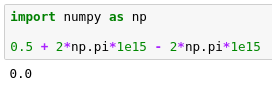
Relevant part of lecture